Projects
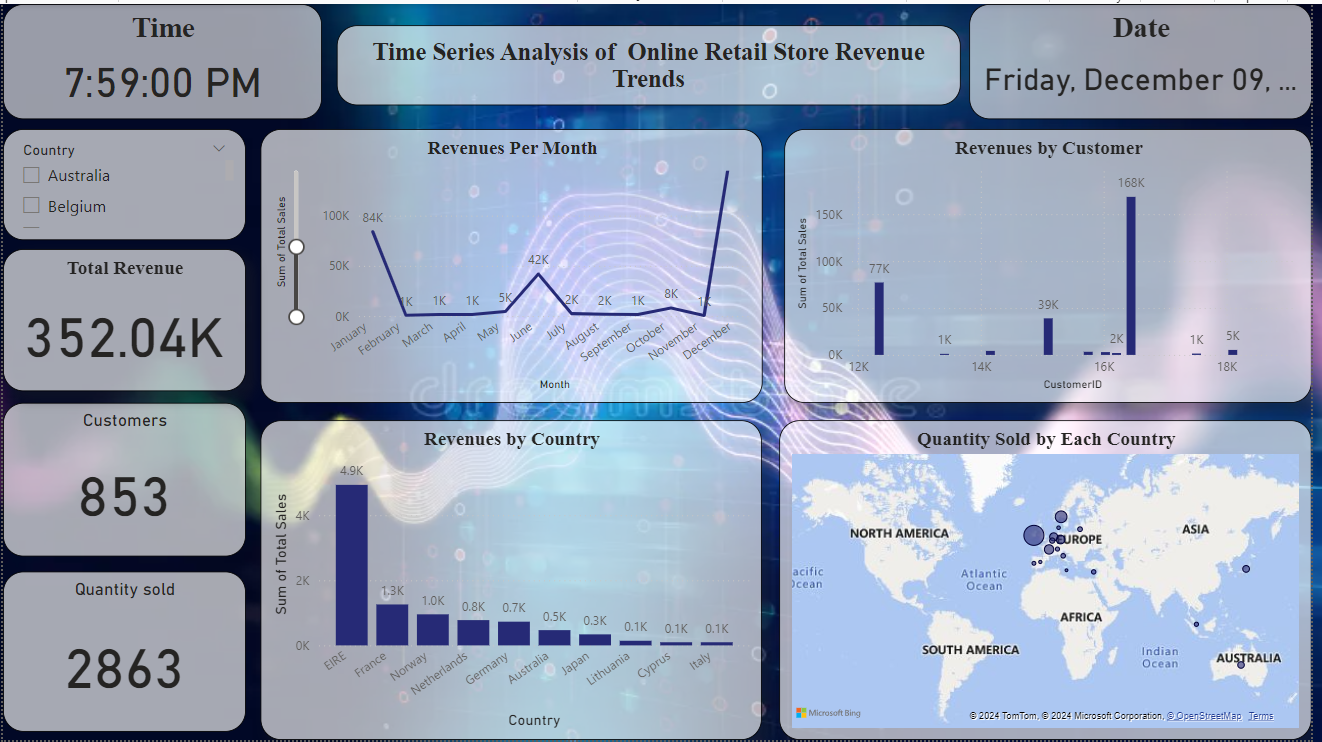
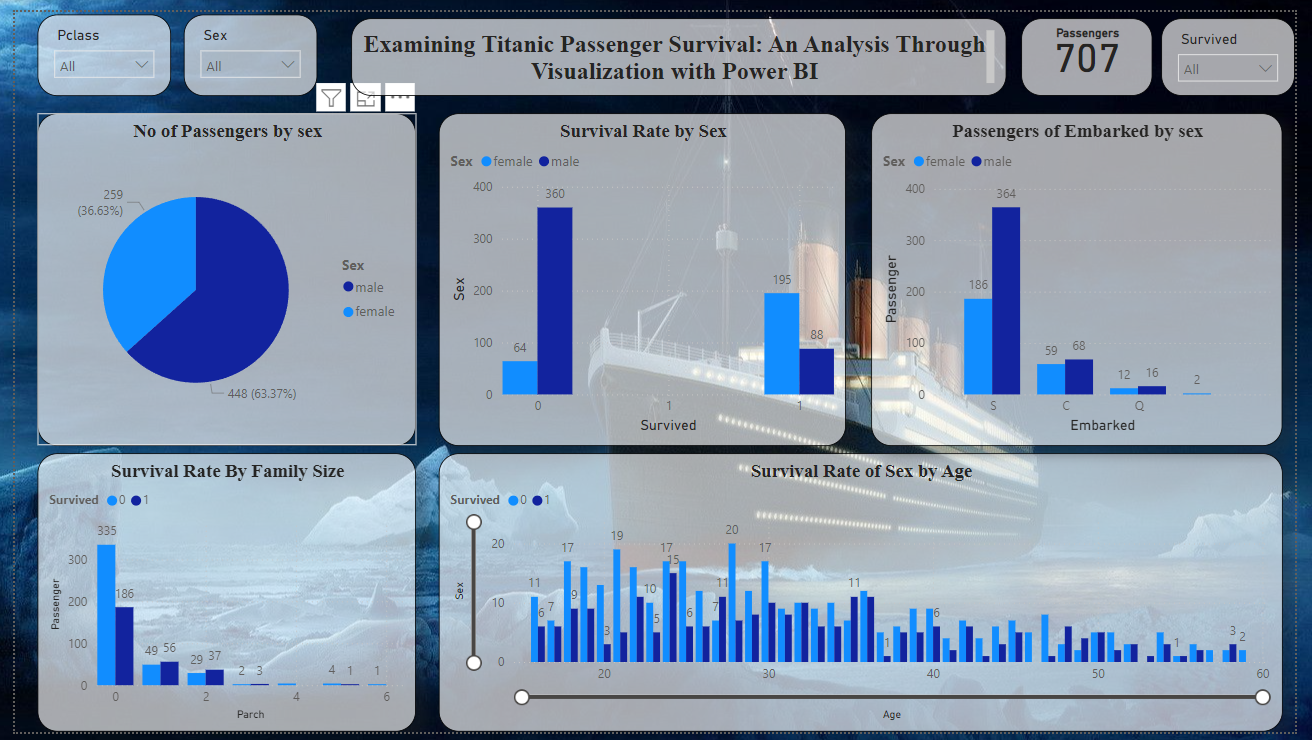
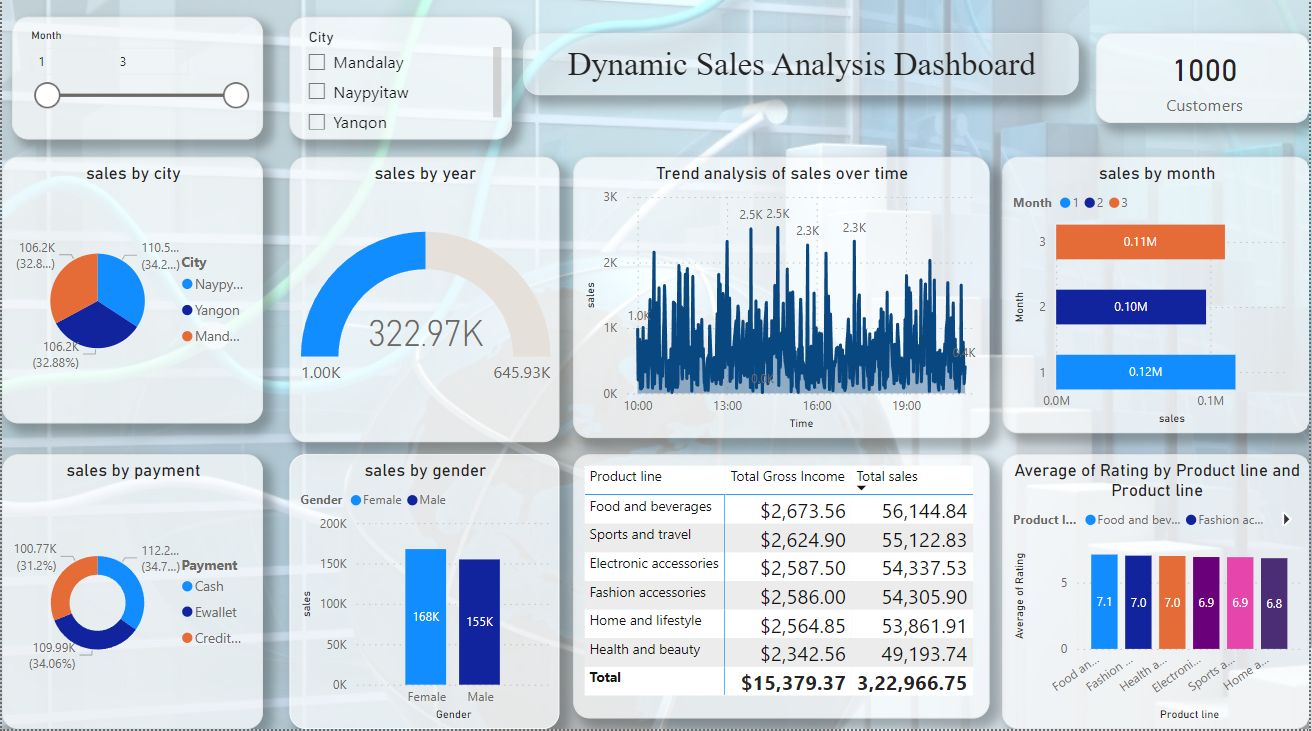
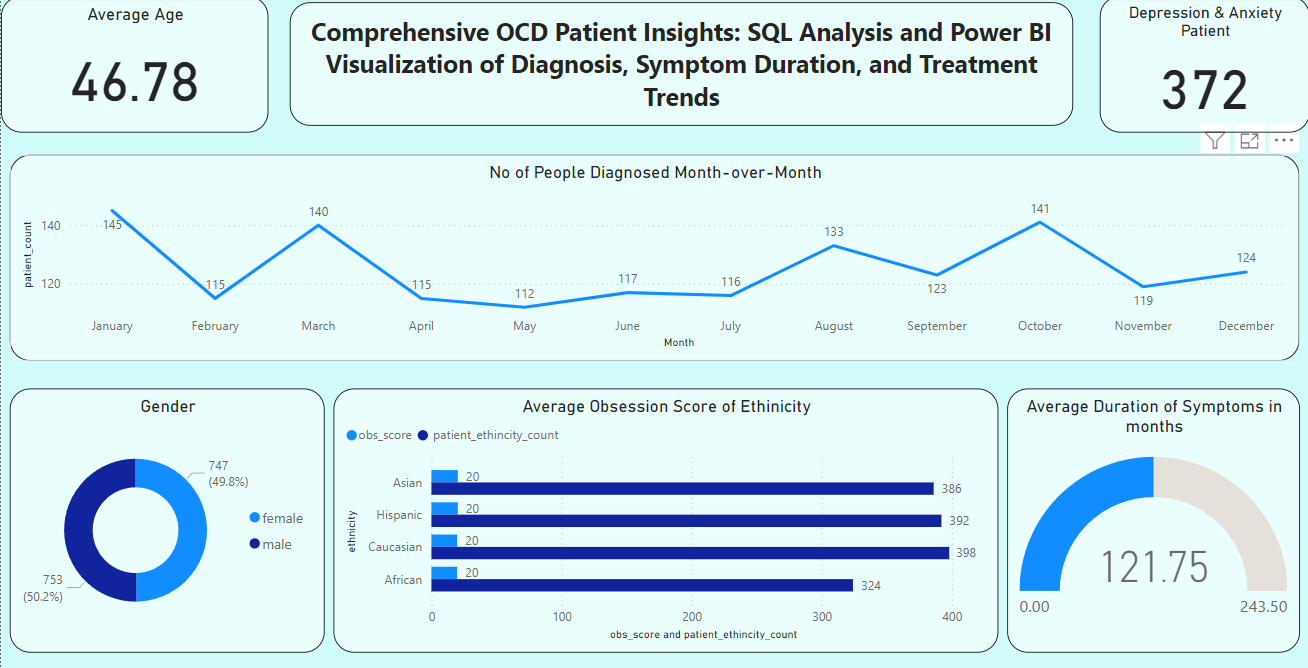












In the semi-supervised gait analysis research, the gait cycle was identified using the slope formula. Each cycle was separated into seven phases, each decided by a percentage formula to assure proper segmentation. The gait phases were then classified using K-means clustering, with labels ranging from 1 to 7. An RNN algorithm was trained and evaluated on the labeled data, resulting in an amazing 98% accuracy.
Gait Cycle Detection: We used the slope formula to identify gait cycles in the data
Phase Segmentation: We used a percentage-based technique to divide each gait cycle into seven separate phases.
Clustering: We used k-means clustering to group the gait stages.
Labeling: The grouped phases were labeled from one to seven.
Model Training and Accuracy: We trained and tested an RNN algorithm on labeled data, and it achieved 98% accuracy.
In the Tamil text summarizing project, the YouTube API was utilized to choose instructional, entertainment, and news content and extract transcripts from the videos. The transcripts were translated into Tamil using Python's translate module, resulting in a dataset of around 1500 entries. NLP approaches such as removing stop words, regex for undesirable letters, and removing English content from the Tamil text were used. Additional NLP techniques, such as vectorization, word embedding, stemming, and lemmatization, were applied. Summarization was performed using sentence transformers, notably X-BERT, and the summarized text was compared to the original using cosine similarity. The model achieved 80% or greater accuracy on 75% of the dataset.
Data Collection: I used the YouTube API to get transcripts of instructional, entertainment, and news videos.
Translation: Transcripts were translated into Tamil using Pandas' translate library, resulting in a dataset of around 1500 entries.
NLP Preprocessing: Used a variety of NLP approaches, including stop word removal, regex cleaning, and English content removal.
Summarization: Text summarization was performed using sentence transformers, notably X-BERT.
Accuracy: Using cosine similarity for evaluation, we achieved above 80% accuracy on 75% of the datase
